Working with SOEP Data¶
Working with Tracking Data (PPFAD)¶
For all years since 1984, the PPFAD data set contains information on all persons who have ever lived in a SOEP household at a survey time (i.e. all respondents, but also children under 17 years of age and persons who have never given an interview). PPFAD is important for the distinction of the research units (persons), especially for longitudinal analyses. In addition, paneldata.org uses PPFAD to differentiate the study population.
Time constant information of persons:
- Never changing Person ID (adults, adolescents, children)
- Original Household Number
- Gender, year of birth, month of birth, year of death if applicable
- Migrant Background
- Sample Membership (psample)
Time-varying information from people:
- Current Household Number: If you move to another household, the household number changes (hhnrakt or $hhnr)
- Survey Status ($netto, $netold)
- Population Membership (private household, institutional households)
- Survey Region (East or West Germany)
The data set is explained in more detail in a documentation:
Create an exercise path with four subfolders:

Example:
- H:/material/exercises/do
- H:/material/exercises/output
- H:/material/exercises/temp
- H:/material/exercises/log
These are used to store your script, log files, datasets and temporary datasets. Open an empty do file and define your created paths with globals:
1 2 3 4 5 6 7 8 9 | ***********************************************
* Set relative paths to the working directory
***********************************************
global AVZ "H:\material\exercises"
global MY_IN_PATH "\\hume\rdc-prod\complete\soep-core\soep.v33.2\stata_en\"
global MY_DO_FILES "$AVZ\do\"
global MY_LOG_OUT "$AVZ\log\"
global MY_OUT_DATA "$AVZ\output\"
global MY_OUT_TEMP "$AVZ\temp\"
|
The global „AVZ“ defines the main path. The main paths are subdivided using the globals “MY_IN_PATH”, “MY_DO_FILES”, “MY_LOG_OUT”, “MY_OUT_DATA”, “MY_OUT_TEMP”. The global “MY_IN_PATH” contains the path to your ordered data.
Based on the data in PPFAD, answer the following questions:
1. Look at the two people with the person ID (variable persnr) 2102 and 19202
a) What gender are they? When were they born and possibly died?
Open the PPFAD dataset. Search the data set for variables that describe gender, year of birth and year of death. Display the information of the variables for persons 2102 and 19202.
1 2 3 4 | use "${MY_IN_PATH}ppfad.dta", clear
* a) What gender are they? When were they born and eventually died?
list persnr sex gebjahr todjahr if persnr == 2102 | persnr == 19202
|

b) Were these people and their parents born in Germany?
In the data set, search for a variable that describes the migration background. Display the information of the variable for persons 2102 and 19202.
1 2 | * b) Were these people and their parents born in Germany?
list persnr migback if persnr == 2102 | persnr == 19202
|

c) If they have immigrated: In which year and from which country?
Search the data set for a variable that describes the country of birth and the year of moving to Germany. Display the information of the variables for persons 2102 and 19202.
1 2 | *c) If they have immigrated: In which year and from which country?
list persnr immiyear corigin if persnr == 2102 | persnr == 19202
|

d) Are these people from East or West Germany?
Search the data set for a variable that describes east-west affiliation. Display the information of the variables for persons 2102 and 19202.
1 2 | *d) Are these people from East or West Germany?
list persnr loc1989 psample if persnr == 2102 | persnr == 19202
|

e) From which sources does the information on the migration background and the year of death come?
Search the data set for info variables that show you sources of information for the year of death and the migration background. Display the information of the variables for persons 2102 and 19202.
1 2 | *e) From which sources does the information on the migration background and the year of death come?
list miginfo todinfo if persnr == 2102 | persnr == 19202
|

2. How many people lived in a realised private household in 2016 and answered the individual questionnaire?
Remember that the wave-specific survey year in SOEP is abbreviated with letters. SOEP started in 1984 (wave a) and was in a survey wave “bg” in 2016. For more information on this topic, please refer to the DTC subchapter Labeling SOEP-Core.
If you are interested in the 2016 survey year, the wave name indicates that you should be interested in variables with the abbreviation “bg”. Search the data set for variables with the abbreviation “bg” that describe the population. Display the characteristics of the population variables:
1 2 3 4 5 6 7 8 9 10 11 12 13 | ********************************************************************************
*** Exercise 2) ***
* How many people lived in a realised private household in 2016 and answered the
* personal questionnaire?
********************************************************************************
* informationen from:
* 2016 -> Wave bg
* private household -> bgpop
* Individual questionnaire -> bgnetto
tab bgpop
|

Values 1 and 2 are relevant to answer the question because they describe realized households. Search the data set for variables with the abbreviation “bg” that describe the survey status. Display the characteristics of the survey status:
1 | tab bgnetto
|

Respondents with survey status between 10 and 15 or survey status 19 completed the individual questionnaire. Cross-tab the variables bgpop and bgnetto with an appropriate restricting condition to answer the question.
1 | tab bgnetto bgpop if ((bgnetto >= 10 & bgnetto <= 15) | bgnetto==19) & (bgpop==1 | bgpop==2)
|

3. PPFAD allows you to see which populations can be viewed from a longitudinal perspective:
a) How many people who answered the individual questionnaire in 2000 also took part in the survey in 2014?
Remember that the wave-specific survey year in SOEP is abbreviated with letters. SOEP started in 1984 (wave a) and was in a survey wave “bg” in 2016. For more information on the subject, see the subchapter Labeling SOEP-Core. The wave name shows that you are interested in the survey years 2000 and 2014. The survey years include the wave names “q”(2000) and “be”(2014). Search the data set for variables with the abbreviations “q” and “be” that describe the survey status. Display the characteristics of the survey status under the condition that the individual questionnaire has been answered:
1 2 3 4 5 6 7 8 9 10 11 | * a)How many people who answered the personal questionnaire in 2000 also took
* part in the survey in 2014?
* informationen from:
* 2000 -> wave q
* 2014 -> wave be
* Individual questionnaire -> $netto
tab qnetto benetto if qnetto>=10 & qnetto<=19 & benetto>=10 & benetto<=19
*or:
//fre qnetto benetto if qnetto>=10 & qnetto<=19 & benetto>=10 & benetto<=19
|

A total of 7639 respondents completed the individual questionnaire in 2000 and 2014.
b) How many people answered the individual questionnaire every year from 2000 to 2014?
The survey years include the wave designations from “q”(2000) to “be”(2014). View the relevant survey status codes to answer the question. Please consider all persons who have answered the individual questionnaire:
1 2 3 4 5 | * b) How many people answered the individual questionnaire every year from 2000
* to 2014?
/* to see all the codes */
lab list bgnetto
|

Define a variable list that shows all survey statuses ($netto) of the 15 survey waves considered in total.
1 2 3 | local v "netto"
local vlist "q`v' r`v' s`v' t`v' u`v' v`v' w`v' x`v' y`v' z`v' ba`v' bb`v' bc`v' bd`v' be`v'"
/* --> 15 waves */
|
Generate a variable that shows the number of waves of completed person interviews. Note that the values 10,12,13,14,15,16,18,19 of the $netto variable mean realized interviews.
1 2 | capture drop h1
egen h1 = anycount(`vlist'), values(10 12 13 14 15 16 18 19)
|
Display a table with its newly generated variable.
1 | tab h1 if h1 == 15
|

A total of 6665 people completed the individual questionnaire every year over the period 2000-2014.
c) How many people who turned 15 in 2011 and lived as children in a survey household took part in the survey in 2016?
The survey year 2011 is represented by the wave “bb” and the survey year 2016 is represented by the wave “bg”. To answer the question, a variable must be generated that identifies people who were 15 years old in 2011. The age of the respondent can be determined with the year of birth and you can limit children using the net code. Generate a variable with people who turned 15 in 2011 and lived in a survey household as a child.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | * c) How many people who turned 15 in 2011 and lived as children in a survey
* household took part in the survey in 2016?
* informationen from:
* 2011 -> wave bb
* Age -> 15
* Child -> bbnetto
* 2016 -> wave bg
* Individual Questionnaire -> bgnetto
/* People who turned 15 in 2011 and lived in a survey household as a child...*/
capture drop a15kind
gen a15kind = 1 if 2011-gebjahr == 15 & bbnetto >= 20 & bbnetto < 30
|
In order to identify all persons who were 15 years old in 2011, lived in a survey household as a child and completed the individual questionnaire in 2016, you must use the net codes again. Create a table from the net code of 2016 to narrow down the cases appropriately.
1 2 3 4 | // fre bgnetto if a15kind == 1 & bgnetto >= 10 & bgnetto < 20
* oder:
tab bgnetto if a15kind == 1 & bgnetto >= 10 & bgnetto < 20
|

In 2016, a total of 309 people who were 15 years old and were part of a survey household as a child in 2011, completed a individual interview.
d) The person with persnr=588010 was born in 1984 in a panel household and was still part of the sample in 2009. The person has changed households twice during this time. In which years?
To identify how often and when a person has changed the household, you must display all available household numbers in ppfad for person 588010.
1 2 3 4 5 6 7 8 9 10 11 12 | * still part of the sample in 2009. The person has changed households twice during
* this time. In which years?
* Information from:
* -> household numbers
list *hhnr if persnr == 588010
/* -> changed household
in year d (1987)
in year y (2008)
no participation since bb (2011)
*/
|

The person 588010 has participated in the survey since the wave “b” (1985) in household 58807. From wave “d” (1987) to wave “x” (2007) the person was in household 73407, from wave “y” (2008) the person was in household 132608.
Generating a cross-section Data Set¶
This example involves generating a data set to analyze health satisfaction determinants in 2008, and you can either use the Paneldata.org syntax generator or write your own syntax file to perform this task. You can search for the variable names in Paneldata.org (or use the variables below directly).
1. Generate a cross-section dataset for the year 2008, which should contain all persons with the following characteristics:
The data set should contain the following variables of interest.
- Satisfaction with health "yp0101"
- Smoking currently yes/no "yp10601"
- current employment status "emplst08"
- monthly household net income "hinc08"
In addition, the data set should contain the following additional information for a 2008 cross-sectional analysis (these variables are automatically generated by paneldata.org):
- Current cross-section weighting factor "yphrf"
- Personal number "persnr"
- Original household number "hhnr"
- Current household number "yhhnr"
- Sample affiliation "psample"
- Gender "sex"
- Year of birth "gebjahr"
Create an exercise path with four subfolders:
Example:
- H:/material/exercises/do
- H:/material/exercises/output
- H:/material/exercises/temp
- H:/material/exercises/log
These are used to store commands, log files, data sets and temporary data sets. Open an empty do file and define your created paths with globals:
1 2 3 4 5 6 7 8 9 | ***********************************************
* Set relative paths to the working directory
***********************************************
global AVZ "H:\material\exercises"
global MY_IN_PATH "\\hume\rdc-prod\complete\soep-core\soep.v33.2\stata_en\"
global MY_DO_FILES "$AVZ\do\"
global MY_LOG_OUT "$AVZ\log\"
global MY_OUT_DATA "$AVZ\output\"
global MY_OUT_TEMP "$AVZ\temp\"
|
The global „AVZ“ defines the main path. The main paths are subdivided using the globals “MY_IN_PATH”, “MY_DO_FILES”, “MY_LOG_OUT”, “MY_OUT_DATA”, “MY_OUT_TEMP”. The global “MY_IN_PATH” contains the path to your ordered data.
Use ppfad as the source file together with the required variables. Keep all cases with completed interviews. In addition, your data set should only contain respondents who can make a statement on the content of the question. For example, you can use the net code to identify and remove children from your data set.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | * * * PFAD * * *
use hhnr persnr sex gebjahr psample yhhnr ynetto ypop using "${MY_IN_PATH}ppfad.dta"
* * * BALANCED VS UNBALANCED * * *
keep if ( (ynetto >= 10 & ynetto < 20) )
* * * PRIATVE VS ALL HOUSEHOLDS * * *
keep if ( (ypop == 1 | ypop == 2) )
* * * SORT PFAD * * *
sort persnr
save "${MY_OUT_TEMP}ppfad.dta", replace
clear
|
Save the modified data record temporarily. Now link your data set with the weights of the SOEP and save your data set as a master file.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | * * * HRF * * *
use "${MY_IN_PATH}phrf.dta"
sort persnr
save "${MY_OUT_TEMP}hrf.dta", replace
clear
* * * CREATE MASTER * * *
use "${MY_OUT_TEMP}ppfad.dta"
merge 1:1 persnr using "${MY_OUT_TEMP}hrf.dta"
drop if _merge == 2
drop _merge
sort persnr
save "${MY_OUT_TEMP}master.dta", replace
clear
|
Now prepare the content variables. Search for the content variables you are looking for from the various data records and temporarily save the created data records.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | * * * READ DATA * * *
use hinc08 yhhnr using "${MY_IN_PATH}yhgen.dta"
sort yhhnr
save "${MY_OUT_TEMP}yhgen.dta", replace
clear
use yp10601 yhhnr yp0101 persnr using "${MY_IN_PATH}yp.dta"
sort persnr
save "${MY_OUT_TEMP}yp.dta", replace
clear
use emplst08 yhhnr persnr using "${MY_IN_PATH}ypgen.dta"
sort persnr
save "${MY_OUT_TEMP}ypgen.dta", replace
clear
|
Link your created data sets to your masterfile and save your analysis data set.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | * * * MERGE DATA * * *
use "${MY_OUT_TEMP}master.dta"
sort yhhnr
merge yhhnr using "${MY_OUT_TEMP}yhgen.dta"
drop if _merge == 2
drop _merge
sort persnr
merge persnr using "${MY_OUT_TEMP}yp.dta"
drop if _merge == 2
drop _merge
sort persnr
merge persnr using "${MY_OUT_TEMP}ypgen.dta"
drop if _merge == 2
drop _merge
* * * DONE * * *
save "${MY_OUT_DATA}my_dataset.dta", replace
desc
|
You have successfully created a cross-sectional data set for the year 2008.
2. Encode missing values into missing values in system failings (STATA)!
In SOEP the missing codes of variables are described in detail with the values -1 to -8. To learn more about missing codes, see the chapter Missing Conventions. For content analyses it is not always necessary to differentiate missing codes. Therefore you should be able to convert missing codes:
1 2 3 4 5 6 7 8 9 10 | use "$MY_OUT_DATA\my_dataset.dta", clear
********************************************************************************
*** Exercise 2) ***
* Encode missing values into missing values in system missings (STATA)!
********************************************************************************
* mvdecode = Change missing values to numeric values and vice versa
mvdecode _all, mv(-1=. \ -2=.t \ -3=.x \ -5=.y \ -8=.z)
|
Open your analysis data set and summarize all missing codes.
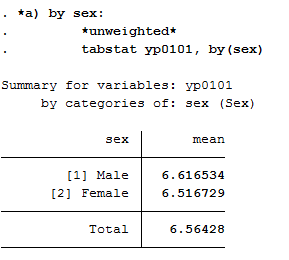
3. How does average health satisfaction differ a) by sex
Satisfaction was measured on a scale of 10. To compare the average satisfaction with health between women and men, you should display the mean value for both sexes.
1 2 | *unweighted*
tabstat yp0101, by(sex)
|
Since you have previously added the SOEP weighting factors to your analysis data set, you should use the weighting for a representative analysis.
1 2 | *weighted*
tabstat yp0101 [aw=yphrf], by(sex)
|

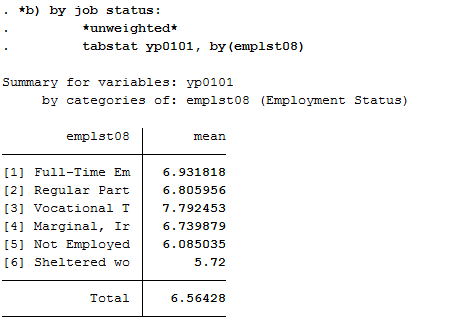
b) Employment status
Now proceed in a similar way when comparing satisfaction with health and employment status. Compare the mean values again:
1 2 3 | *b) by job status:
*unweighted*
tabstat yp0101, by(emplst08)
|
Since you have previously added the SOEP weighting factors to your analysis data set, you should use the weighting for a representative analysis.
1 2 | *weighted*
tabstat yp0101 [aw=yphrf], by(emplst08)
|

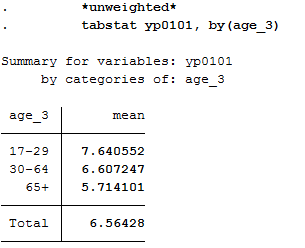
c) Age
Since you do not have a variable that represents the age, you must generate a suitable age variable using the Birth year variable. The year of birth is metric and should be categorized for analysis. Define categories for your age variable and assign suitable labels.
1 2 3 4 5 6 7 | *c) by age in 2008 (<30, 30-64, 65+)
gen age=2008-gebjahr
gen age_3=age
recode age_3 (17/29=1) (30/64=2) (65/120=3)
label define age_3 1 "17-29" 2 "30-64" 3 "65+"
label values age_3 age_3
|
Create a mean value comparison with your age variable and health satisfaction in weighted and unweighted form.
1 2 | *unweighted*
tabstat yp0101, by(age_3)
|
1 2 | *weighted*
tabstat yp0101 [aw=yphrf], by(age_3)
|

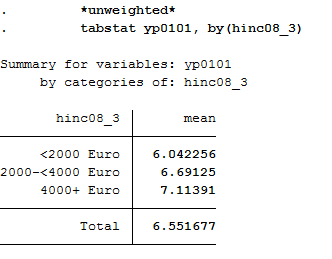
d) Income
As with age, generate a categorized version of the income for the household net income:
1 2 3 4 5 | *d) by monthly houshold net income (-1.999, 2.000-3.999, 4000+ Euro)
gen hinc08_3 = hinc08
recode hinc08_3 (0/1999=1) (2000/3999=2) (4000/99999=3)
label define hinc08_3 1 "<2000 Euro" 2 "2000-<4000 Euro" 3 "4000+ Euro"
label values hinc08_3 hinc08_3
|
Display the mean values in weighted and unweighted form:
1 2 | *unweighted*
tabstat yp0101, by(hinc08_3)
|
1 2 | *weighted*
tabstat yp0101 [aw=yphrf], by(hinc08_3)
|
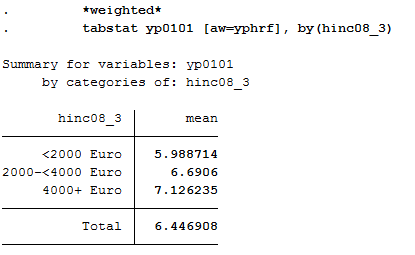
e) Smoking
Since this variable is nominal, adjustments to this variable are not necessary. Display the average satisfaction with health for smokers and non-smokers in weighted and unweighted form:
1 2 3 4 | *e) by smoking yes/no
*unweighted*
tabstat yp0101, by(yp10601)
|

1 2 | *weighted*
tabstat yp0101 [aw=yphrf], by(yp10601)
|

Working with Migration Data (BIOIMMIG)¶
With its migration and refugee samples, SOEP provides a broad spectrum of information on persons with a refugee and migration background.
In the BIOIMMIG data set you will find relevant information on the history of flight and migration, such as motives for fleeing and migration, the circumstances after arrival in Germany, but also information on relatives in the country of origin and the desire to return to the country of origin in edited form. For more information about this data set and a list of the variables it contains, see the BIOIMMIG Documentation.
In the following, we will use this record and other information from the SOEP to create a status variable that you can use to distinguish whether or not people with a migration background also have an escape background.
Create an exercise path with four subfolders:
Example:
- H:/material/exercises/do
- H:/material/exercises/output
- H:/material/exercises/temp
- H:/material/exercises/log
These are used to store commands, log files, data sets and temporary data sets. Open an empty do file and define your created paths with globals:
1 2 3 4 5 6 7 8 9 | ***********************************************
* Set relative paths to the working directory
***********************************************
global AVZ "H:\material\exercises"
global MY_IN_PATH "\\hume\rdc-prod\complete\soep-core\soep.v33.2\stata_en\"
global MY_DO_FILES "$AVZ\do\"
global MY_LOG_OUT "$AVZ\log\"
global MY_OUT_DATA "$AVZ\output\"
global MY_OUT_TEMP "$AVZ\temp\"
|
The global „AVZ“ defines the main path. The main paths are subdivided using the globals “MY_IN_PATH”, “MY_DO_FILES”, “MY_LOG_OUT”, “MY_OUT_DATA”, “MY_OUT_TEMP”. The global “MY_IN_PATH” contains the path to your ordered data.
Task 1: Preparation of BIOIMMIG
a) In which variable can you find information about the status of each person when they immigrated to Germany?
Open the record or browse the BIOIMMIG documentation and search for a variable describing the immigration status. The biimgrp variable from the BIOIMMIG data set is the appropriate variable.
1 2 3 4 5 6 7 8 9 | *** Exercise 1 ******************************************************************
/*
a) In which variable can you find information about the status of each person when they immigrated to Germany?
*/
* Immigration status is stored in the variable biimgrp.
use $MY_IN_PATH\bioimmig.dta, clear
|
b) Identify this variable in the BIOIMMIG data set and load it from the data set, together with the person number and the survey year.
Open your data set only with the required variables to maintain clarity in your analysis data set.
1 2 3 4 5 | /*
b) Identify this variable in the BIOIMMIG data set and load it from the data set, together with the person number and the survey year.
*/
use persnr syear biimgrp using $MY_IN_PATH\bioimmig.dta, clear
|
c) What are the values of this variable?
Familiarize yourself with your research-relevant analysis variable and check coding and case numbers.
1 2 3 4 5 | /*
c) What are the values of this variable?
*/
tab biimgrp, m //Characteristics of the variable are examined.
|

d) On the basis of this variable, generate the variable “Escape”, which only distinguishes between three groups:
- 0 = Cases where no information is available
- 1 = All persons without escape background
- 2 = Asylum seekers / fugitives
After you have familiarized yourself with the research-relevant analysis variable, recode the variable to suit your project. Then check the case numbers of your generated variable with the source variable.
1 2 3 4 5 6 7 8 9 | /*
d) On the basis of this variable, generate the variable "Escape", which only distinguishes between three groups:
0 = Cases where no information is available
1 = All persons without escape background
2 = Asylum seekers / refugees
*/
recode biimgrp (-5 -2 -1 = 0 "No Answer") (1 2 3 4 6 = 1 "no Escape") (5 = 2 "Escape"), gen(Escape)
tab biimgrp Escape, m // biimgrp and escape are compared.
|

e) It may happen that initially there is no information on the status of immigration, but this will change in a later year. Limit the data record to the last observation that is available for the respective person, since this way the specification with the most information content is used.
1 2 3 4 5 6 7 8 | e) It may happen that tinitially there is no information on the status of
* immigration, but this will change in a later year. Limit the data record to
* the last observation that is available for the respective person, since this
* way the specification with the most information content is used.
*/
bysort persnr: egen syear_max = max(syear) //A variable is created, which shows the last existing yearly observation
keep if syear_max == syear //Annual observations which are not the last observation are deleted.
|
f) Save the generated data record on your personal drive temporarily .
1 2 3 4 | f) Save the generated data record on your personal drive temporarily
*/
save $MY_OUT_TEMP\biimgrp.dta, replace
|
Aufgabe 2: Add basic variables from PPFAD and weights
a) Load the following information from PPFAD:
- Never changing Person ID "persnr"
- Household number "hhnr" and the current household number "bghhnr"
- The net variable with information about the interview type "bgnetto"
- The sex of the person "sex"
- The year of birth "gebjahr"
- Variables on the migration background "migback" , "germborn" , "corigin" , "immiyear"
- Information about the survey status: "psample"
If you want to familiarize yourself with the PPFAD data set, visit the chapter Working with Tracking Data (PPFAD).
1 2 3 4 5 6 7 8 9 10 11 12 | /*
a) Use the following information from PPFAD:
- Never changing Person ID „persnr“
- Household number "hhnr" and the current household number "bghhnr".
- the net variable with information about the interview type "bgnetto".
- the sex of the person "sex"
- the year of birth "semester"
- Variables on the migration background "migback", "germborn" "corigin" "immiyear"
- Information about the survey status: "bgnetto" and "psample".
*/
use persnr hhnr bghhnr bgnetto psample sex gebjahr germborn corigin immiyear migback using $MY_IN_PATH\ppfad.dta, clear
|
b) Merge the previously generated data record using the person number.
If you don’t understand how to create your own cross-section dataset, visit the chapter Generating a cross-section Data Set.
1 2 3 4 5 | /*
b) Merge the previously generated data record using the person number.
*/
merge 1:1 persnr using $MY_OUT_TEMP\biimgrp.dta, nogen
|
c) Add the corresponding person extrapolation factors to the data record.
1 2 3 4 | c) Add the corresponding person extrapolation factors to the data record.
*/
merge 1:1 persnr using $MY_IN_PATH\phrf.dta, keepus(bgphrf) nogen
|
d) Only keep respondents for whom a youth or individual questionnaire was realized in 2016.
For example, to exclude children who have not provided immigration status information, use the net code from PPFAD. Only keep persons who have conducted a completed individual or youth interview.
1 2 3 4 5 6 7 | /*
d) Only keep individuals for whom a youth or personal questionnaire was realized in 2016.
*/
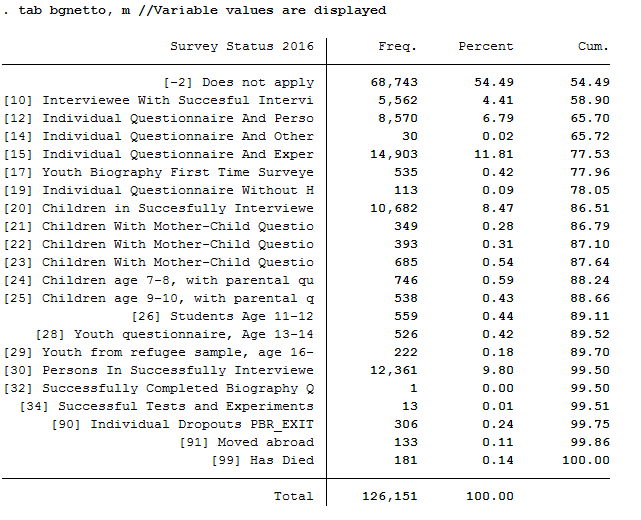
tab bgnetto, m //Variable values are displayed
keep if inrange(bgnetto, 10, 19) // People who have a code between 10 and 19 will be kept.
|
Task 3: Generate a status variable with the following categories:.
- No immigrant background
- Migration 2nd generation
- Immigration without information
- Immigration, not flight
- Immigration, Flight
To generate this status variable, check the contents of the existing migration variables from PPFAD (migback germborn).
1 2 3 4 5 | /*
Generate a status variable with the following categories:
*/
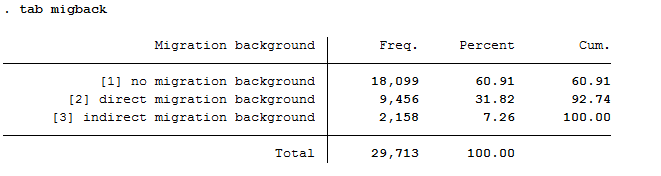
tab migback
|
1 | tab germborn
|

Use the migration variables from PPFAD (migback, germborn) and link this information with your previously generated escape variable to build the described status variable from Task 3.
1 2 3 4 5 6 7 8 9 | gen Status = 0 // All persons will first receive the missing code for "no info".
replace Status = 1 if migback == 1 & germborn == 1 // "no migback"
replace Status = 2 if migback == 3 // "2nd generation" (2nd generation migrants born by definition in Germany, therefore "& germborn == 1" here unnecessary
replace Status = 3 if germborn == 2 & Escape == 0 // "Immigrants without information"
replace Status = 4 if germborn == 2 & Escape == 1 // "Immigrants, no escape"
replace Status = 5 if germborn == 2 & Escape == 2 // "Immigrant, escape"
label def Statuslbl 0"no info" 1"no migback" 2"2. Generation" 3"Immigrants without information" 4"Immigrants, no escape" 5"Immigrant, escape"
label val Status Statuslbl // Values of the status veriable receive label
|
Task 4: Content analysis:
a) How many refugees (foreign-born with refugee/asylum titles) are now in your record?
Look at your status variable previously generated in task 3 to answer the question
1 2 3 4 5 6 7 | *** Exercise 4 ******************************************************************
/*
a) How many refugees (foreign-born with refugee/asylum titles) are now in your record?
*/
tab Status, m //Display Generated Status Variable
|
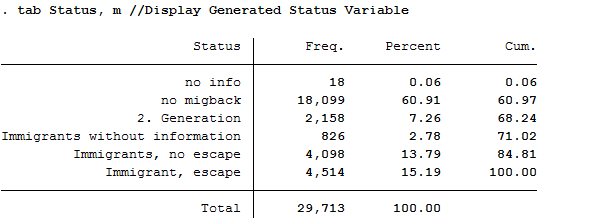
All 4,514 respondents who received the value 5 for the generated status variable have a direct migration background (migback==2), were not born in Germany (germborn==2) and fled their home country (flight==2 and biimgrp==5).
b) How many are there if you take the person extrapolation factors into account? Interpret the results.
Look at your status variable previously generated in task 3 to answer the question
1 2 3 4 5 | /*
b) How many are there if you take the person extrapolation factors into account? Interpret the results.
*/
tab Status [aw=bgphrf], m //Display generated status variable weighted with analytic weights
|

After weighting, there are only about 675 fugitives in the data set. The weighting thus corrected the number of fugitives downwards.
c) How many persons are represented by the sample taking the extrapolation factors into account?
To use frequency weights in STATA, integer weights are required. Create an integer frequency weight from the weighting factor provided so that you can make representative statements. Then take a look at the new results.
1 2 3 4 5 6 | /*
c) How many persons are represented by the sample taking the extrapolation factors into account?
*/
gen fweight = round(bgphrf) //Frequency weights for stata require integer weight
tab Status [fw=fweight], m //Display generated status variable weighted with frequency weights
|

Around 1,600,000 people are represented.
d) What is the proportion of people over 40 years of age among the fugitives?
Since the data in this exercise come from the wave “bg”, we are currently in the survey year 2016; if you need a description of the wave designations, please refer to the chapter Labeling SOEP-Core. To generate a suitable age variable, you can use the year of birth (year of birth). If we look at the survey year 2016, all persons born in 1976 or earlier were over 40 years old. Generate a suitable age variable and look at the proportion of fugitives over 40 years of age in weighted form:
1 2 3 4 5 6 7 8 | /*
d) What is the proportion of people over 40 years of age among the fugitives?
*/
gen ue_40 = 0
replace ue_40 = 1 if gebjahr <= 1976 // Persons receive proficiency 1 if they were born before 1975.
tab Status ue_40 [aw=bgphrf], m row nofreq
|
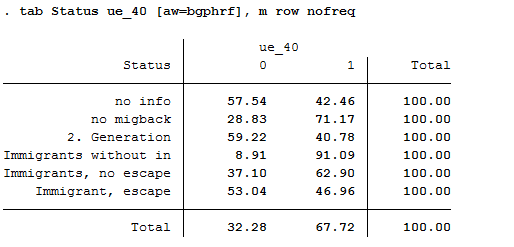
The proportion of refugees over 40 years of age is about 47%.
Generating a longitudinal Data Set¶
This example is about generating a data set to analyze determinants of health satisfaction. You can either use the syntax generator of paneldata.org or write a syntax file yourself. You can search for variable names in Paneldata.org.
In the previous examples you have already created an exercise path with four subfolders, as well as corresponding globals in the STATA do-file. You can use the same folders and globals for this exercise.
1.Generate an unbalanced panel dataset for the years 2006 to 2008 using paneldata.org if you wish. The data set should contain all respondents in private households:
The data set should contain the following variables of interest:
- Health satisfaction "wp0101" "xp0101" "yp0101"
- Smoking at present yes/no "wp9301" "yp10601"
- Current employment status "emplst06" "emplst07" "emplst08"
- Monthly household net income "hinc06" "hinc07" "hinc08"
In addition, the data set should include the following additional information for analysis from 2006 to 2008:
- Cross-sectional weighting factors for all relevant years "wphrf" "xphrf" "yphrf"
- Person ID "persnr"
- Original household number "hhnr"
- Household number for all relevant years "whhnr" "xhhnr" "yhhnr"
- Sample membership "psample"
- Sex "sex"
- Year of birth "gebjahr"
- population membership "wpop" "xpop" "ypop"
If you need detailed instructions on how the script generator works in paneldata.org, you can find them in the chapter Syntax Generator on paneldata.org.
If you would like to assemble your data set yourself, you can do this with the data sets you have supplied. From the previous exercise with tracking data, you may already have an idea where to get most of the variables.
Since we want to have an unbalanced panel record, the $netto variable for the years 2006 to 2008 must also be used. In addition, our analysis must limit population membership, as we are only interested in household respondents.
Tip
If a data set is created from several variables of different data sets, it is worth sorting the person number before saving the individual data sets in order to be able to merge the data sets more easily afterwards.
1.1. Create a Master-Files
Use ppfad as the source file together with the required variables that you may have already researched in Paneldata or identified from the variable label of the data set. Note that only variables of the years to be analyzed should be used.
1 2 3 |
use hhnr persnr sex gebjahr psample xhhnr xnetto xpop yhhnr ynetto ypop whhnr wnetto wpop using "${MY_PATH_IN}ppfad.dta"
|
Since we want to receive an unbalanced data set, i.e. persons who have completed a personal questionnaire at least once within the 3 years, you must restrict the variable $netto (survey status). Also, we only want to analyze private households, so we need a further restriction of the $pop (sample membership) variable.
1 2 3 4 5 6 7 8 |
keep if ( (xnetto >= 10 & xnetto < 20) | (ynetto >= 10 & ynetto < 20) | (wnetto >= 10 & wnetto < 20) )
* * * PRIVATE VS ALL HOUSEHOLDS * * *
keep if ( (xpop == 1 | xpop == 2) | (ypop == 1 | ypop == 2) | (wpop == 1 | wpop == 2) )
|
Then we sort the persnr (personal number) of the data record and save it.
1 2 3 4 5 |
sort persnr
save "${MY_PATH_OUT}ppfad.dta", replace
clear
|
What is still missing is the cross-section weighting factor and the variables of interest in terms of content. To apply the weighting factors to the data set, open the weighting data set for the person level phrf, sort it and save it again.
1 2 3 4 5 6 |
use persnr wphrf xphrf yphrf using "${MY_PATH_IN}phrf.dta"
sort persnr
save "${MY_PATH_OUT}phrf.dta", replace
clear
|
Now we come to the variables of content. In order not to have to click through all delivered data sets, it is recommended to enter the label of the variable of interest on paneldata.org.
Use the filter to narrow your search. Select our main study SOEP Core, the search type “variable”, the analysis unit “p” or “h” and the corresponding year. Once you have clicked on the year of interest, a variable history is displayed. You can use this to see in which years the variable was collected and what the variable is called.
Example: Variable Label „Satisfaction Health“
Example: Variable Label „currently smoking yes/no“
Example: Variable Label „current employment status“
Example: Variable Label „monthly net household income“

To merge the data you can either use the script generator on paneldata.org or write the syntax manually into a do-file.
We now have all the information we need to create a master file. As already mentioned with TIP!, it is recommended to save the data records sorted by the persnr (person number) before merging.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | use persnr wp0101 wp9301 using "${MY_PATH_IN}wp.dta"
sort persnr
save "${MY_PATH_OUT}wp.dta", replace
clear
* * * Persons 2007 * * *
use persnr xp0101 using "${MY_PATH_IN}xp.dta"
sort persnr
save "${MY_PATH_OUT}xp.dta", replace
clear
* * * Persons 2008 * * *
use persnr yp0101 yp10601 using "${MY_PATH_IN}yp.dta"
sort persnr
save "${MY_PATH_OUT}yp.dta", replace
clear
|
With the help of a unique indicator, which is either the household number ($hhnr) or the person number (persnr), you can now merge all data records or individual variables to ppfad. Which indicator to use and when depends on the unit of analysis. Since we are on the person level, our indicator is persnr (person ID).
We load the dataset ppfad and merge our datasets or variables to ppfad.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
merge 1:1 persnr using "${MY_PATH_OUT}phrf.dta", keep(master match) nogen
* merge data from $p.dta
merge 1:1 persnr using "${MY_PATH_IN}/wp.dta", keepus(wp0101 wp9301) keep(master match) nogen // health & smoking
merge 1:1 persnr using "${MY_PATH_IN}/xp.dta", keepus(xp0101) keep(master match) nogen // health
merge 1:1 persnr using "${MY_PATH_IN}/yp.dta", keepus(yp0101 yp10601) keep(master match) nogen // health & smoking
* merge data from $pgen.dta
local y = 6
foreach wave in w x y {
merge 1:1 persnr using "${MY_PATH_IN}/`wave'pgen.dta", keepus(emplst0`y')nogen keep(master match)
local y = `y' + 1
}
* merge data from $hgen.dta
local y = 6
foreach wave in w x y {
merge m:1 `wave'hhnr using "${MY_PATH_IN}/`wave'hgen.dta", keepus(hinc0`y') nogen keep(master match)
local y = `y' + 1
}
|
2. Encode missing values in system failings (STATA)!
After the master file has been created with all required information, the missing values, which can take between -1 to -8 in SOEP, must be recoded into missings. This step is important for converting a wide-format data set to a long format.
1 2 3 4 5 6 | ********************************************************************************
*** Task 2) ***
* Encode missing values in system failings (STATA)!
********************************************************************************
mvdecode _all, mv(-1=. \ -2=.t \ -3=.x \ -5=.y \ -8=.z)
|
3. The data set is in wide-format, i.e. additional years are displayed as additional variables (columns). For many analyses it makes sense to convert data sets into the long format. In long format, additional years are displayed as additional lines. If the data record covers three years, as in this example, there are three lines for each person. Convert the data set to long format using the STATA command reshape.!
Since these are cross-section variables, it can be assumed that each variable has at least one wave abbreviation, which makes the variable unique. Conversely, this means that the variables must be renamed before the reshape command.
Before renaming all original variables (e.g. from $P data records) it must be checked whether the question and the answer categories were the same in all years (you can also look up the exact wording of the question in the corresponding questionnaire). If changes are made, the variables may have to be recoded.
1 2 3 4 | *Check if original variable have changed over time
tab1 wp0101 xp0101 yp0101
tab1 wp9301 yp10601
/*additionally check questionaires for exact wording*/
|
How you rename the variables is largely up to you. However, you should ensure that the name remains consistent over time and that the variable only differs according to the year (variable name + four-digit year suffix, e.g. zufr2006, zufr2007, zufr2008). You can rename the variables either manually, line by line, or for advanced users using a loop.
Example of manual renaming:
1 2 3 4 5 6 7 8 | *rename time-variant variables
*with examples how to use loops (but can also be done "manually")
rename wp9301 smoke2006
rename yp10601 smoke2008
rename wp0101 health2006
rename xp0101 health2007
rename yp0101 health2008
...
|
Example of a loop:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | foreach x in 6 7 8 {
rename hinc0`x' hinc200`x'
rename emplst0`x' emplst200`x'
}
local y=2006
foreach w in w x y {
rename `w'hhnr hhnrakt`y'
rename `w'netto netto`y'
rename `w'pop pop`y'
rename `w'phrf phrf`y'
local y=`y'+1
}
|
3.1. The reshape-command
Now that we have made all relevant preparations, you can start to convert the data set. If you want to convert a data set, you can do this in both directions:

In our case we reshap from wide to long. This means that a new variable name must be assigned for the year of the survey (j). The variable is then generated automatically. Currently, each person is assigned a line in Stata.
| persnr | hhnr | wave | sex | smoke2006 | smoke2008 |
|---|---|---|---|---|---|
| 12345 | 123 | x | m | yes | yes |
| 54321 | 211 | x | m | no | no |
1 2 3 4 | *reshape dataset to long-format
reshape long health smoke emplst hinc netto pop hhnrakt phrf, i(persnr) j(year)
bys persnr: gen waves=_N /*additional information: count number of waves per person*/
tab waves
|
After the reshape command you have one line per year for each person:
| persnr | hhnr | wave | year | sex | smoke |
|---|---|---|---|---|---|
| 12345 | 123 | x | 2006 | m | yes |
| 12345 | 123 | y | 2007 | m | . |
| 12345 | 123 | z | 2008 | m | yes |
4. Perform analyses based on the data. Try to answer the following questions:
a. Has average satisfaction with men’s and women’s health changed over the three years?
Satisfaction with health was measured on a scale of 10, with a value of 10 representing an extraordinarily high level of satisfaction. To compare the average satisfaction with health between women and men, you should display the mean value for both sexes. The mean value is displayed weighted here.
1 2 3 4 | *a) Has the average satisfaction with men's health and women changed
* over the three years?
mean health [pw=phrf], over(sex year)
|
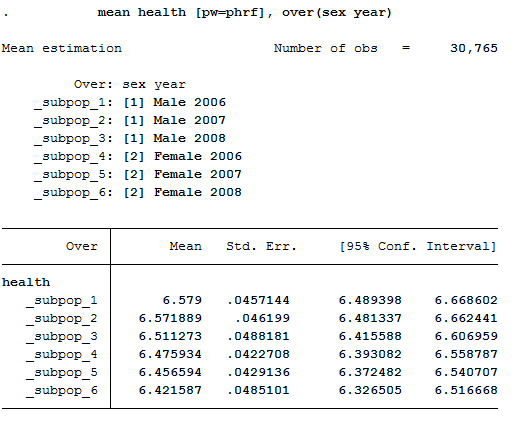
The output shows the average values for men and women for all three years. The first three values show average satisfaction with men’s health between 2006 and 2008, while the last three values show average satisfaction with women’s health.
b. What is the proportion of people for whom health satisfaction has increased from 2006 to 2007?
To answer this question, the difference between 2006 and 2007 should be displayed. You should make sure that only within one persnr (person ID) and the satisfaction of the following year should be analyzed.
1 2 3 4 5 | *b) What is the proportion of people for whom health satisfaction has increased
* from 2006 to 2007??
sort persnr year
gen diff=health-health[_n-1] if persnr==persnr[_n-1] & year==year[_n-1]+1
tab diff if year==2007 /*unweighted*/
|
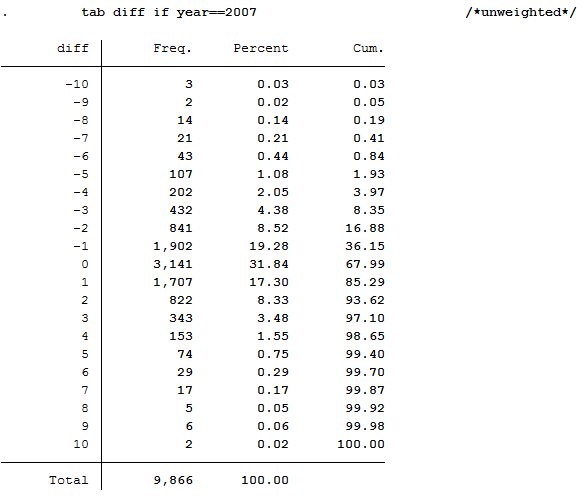
Since you have previously added the SOEP weighting factors to your analysis data set, you should use the weighting for a representative analysis.
1 | tab diff if year==2007 [aw=phrf] /*weighted*/
|
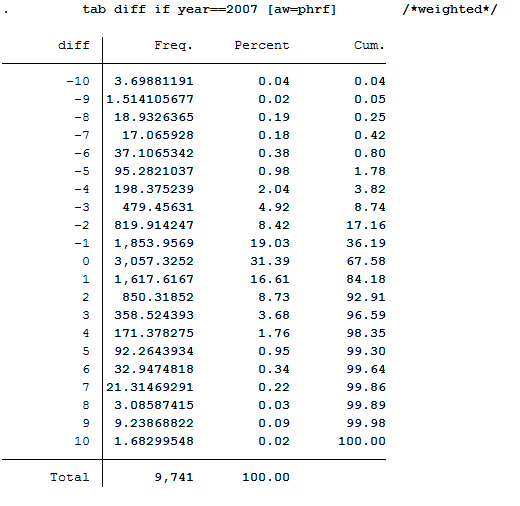
The values less than 0 show a deterioration in health satisfaction. The value 0 means a constant health satisfaction and all values above 0 show a positive change in satisfaction with their health. With a value of 10, it can be assumed that these people were interviewed for the first time in 2007 or 2008.
c. In what direction and how much has satisfaction with the health of people who quit smoking after 2006 changed from 2006 to 2008?
The procedure is similar to the previous question, except that the element “smoke yes/no” is added.
1 2 3 4 5 6 7 8 9 10 11 12 | *c) In what direction and how much has satisfaction with the health of
* people who quit smoking after 2006 changed from 2006 to 2008?
gen diff2=health-health[_n-2] if persnr==persnr[_n-2] & year==year[_n-2]+2 & year==2008
gen quit=.
replace quit=0 if smoke==1 & smoke[_n-2]==1 & persnr==persnr[_n-2] & year==year[_n-2]+2 & year==2008
replace quit=1 if smoke==2 & smoke[_n-2]==1 & persnr==persnr[_n-2] & year==year[_n-2]+2 & year==2008
replace quit=2 if smoke==2 & smoke[_n-2]==2 & persnr==persnr[_n-2] & year==year[_n-2]+2 & year==2008
replace quit=3 if smoke==1 & smoke[_n-2]==2 & persnr==persnr[_n-2] & year==year[_n-2]+2 & year==2008
label define quit 0 "smoker" 1 "quit" 2 "non-smoker" 3 "begin"
label values quit quit
tabstat diff2, by(quit)
|
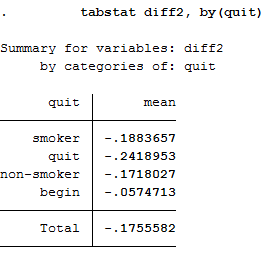
To obtain a weighted mean value, address the analysis weight after the generated variable.
1 | tabstat diff2 [aw=phrf], by(quit) /*weighted*/
|
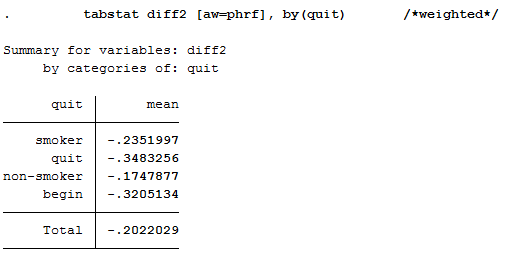
This illustration shows the mean of the health variable under the condition of the variable quit we generated beforehand. With a mean of -0.24 (weighted -0.35) the biggest change in health satisfaction is seen in people who quit smoking after 2006. For example, if a person smoked in 2006 and indicated a satisfaction value of 8, the person after he/she stopped smoking in 2008 indicates a satisfaction value of 7.76. So you can assume that when a person stops smoking, the state of health that a person perceives deteriorates. Now we have to test if the assumption is correct.
d. Does quit smoking make your health worse? To what extent can the result of the analysis “Stop smoking” be distorted?
In order to establish a connection between health satisfaction and stopping smoking, one should use the ttest or to be more specific, the one-sample t test. It checks whether the mean value of a sample deviates significantly from a known expected value (specified in the null hypothesis).
1 2 3 4 5 | *d) Does quitting smoking make your health worse? To what extent can the
* result of the analysis "Stop smoking" be distorted?
* Notes: So far we have not tested whether the difference is statistically significant
ttest diff2==0 if quit==1
|

H0 Hypothesis: If one stops smoking it has no effect on health.
For this test we assume a 95% probability. What we want to check now is whether the H0 hypothesis can be rejected or not. If you look at the output of the test, you first see the mean value of value 1 (quit smoking) of the variable quit. The last line of the output shows the significance level. If it falls below the value 0.05, one can speak of a statistically significant result. In our example, the null hypothesis can be discarded because its value is less than 0.05 percent. So quitting smoking has a significant impact on a person’s perceived health.
Longitudinal Data Analysis¶
Simple cross section analyses show that married people have a higher life satisfaction than singles. You want to check this on the basis of longitudinal analyses with the SOEP.
Create an exercise path with four subfolders:
Example:
- H:/material/exercises/do
- H:/material/exercises/output
- H:/material/exercises/temp
- H:/material/exercises/log
These are used to store your script, log files, datasets and temporary datasets. Open an empty do file and define your created paths with globals:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | ***********************************************
* Set some useful commands
***********************************************
version 13
clear all
set more off
**increase buffer size
set scrollbufsize 2000000
**now restart stata!
***********************************************
* Set relative paths to the working directory
***********************************************
global AVZ "H:\material\exercises"
global MY_IN_PATH "\\hume\rdc-prod\distribution\soep-long\soep.v33.1\stata_en\"
global MY_DO_FILES "$AVZ\do\"
global MY_LOG_OUT "$AVZ\log\"
global MY_OUT_DATA "$AVZ\output\"
global MY_OUT_TEMP "$AVZ\temp\"
|
The global „AVZ“ defines the main path. The main paths are subdivided using the globals “MY_IN_PATH”, “MY_DO_FILES”, “MY_LOG_OUT”, “MY_OUT_DATA”, “MY_OUT_TEMP”. The global “MY_IN_PATH” contains the path to your ordered data.
Create a master file that uses the important variables from ppfadl.
You should always add some variables from PPFADL to your data set by default. Download the following information from PPFADL:
- Person ID "pid"
- Household number "hid"
- Survey year "syear"
- The net variable with information on the interview type "netto"
- The weighting variable "phrf"
- The sex of the person "sex"
- The migration background "migback"
1 2 3 4 | *-------------------------------------------------------------------------------
*** Step 1) Start with basic information from PPFADL ***
use pid hid syear netto phrf migback sex using ${MY_IN_PATH}\ppfadl.dta
|
Search for matching variables and add them to your data set
To perform your analysis, you need different SOEP variables. The SOEP offers various options for a variable search:
- Search the questionnaires for useful variables. (for more information visit the chapter Variable Search with Questionnaires)
- Find a suitable variable via the topic list of paneldata.org (for more information visit the chapter Topic Search with paneldata.org)
- Search for a suitable variable using a search term in paneldata.org (for more information visit the chapter Variable Search with paneldata.org)
- Use the documentation provided by the generated variables (for more information visit the chapter Documentation of Generated Data)
In this case you need the variables "pgfamstd" (martial status) and "plh0182" (life satisfaction).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | *-------------------------------------------------------------------------------
*** Step 2) Add the relavant variables: here: family status and life satisfaction ***
merge 1:1 pid syear using ${MY_IN_PATH}\pgen, keepusing(pgfamstd) keep(1 3) nogen
// merges family status from pgen
// Documentation for PGEN can be found here
// http://panel.gsoep.de/soep-docs/surveypapers/diw_ssp0307.pdf)
*describe using pl (directory)
// for checking out variable names without opening the dataset
merge 1:1 pid syear using ${MY_IN_PATH}\pl, keepusing(plh0182) keep(1 3) nogen
// merges life satisfaction from pl
save $MY_OUT_DATA\ppfad.dta, replace
|
Clean and inspect the data
Recode all missings into the format of a point.
1 2 3 | *-------------------------------------------------------------------------------
*** Step 3) Clean and inspect the data
mvdecode _all, mv(-8/-1)
|
Since you are interested in individual characteristics in your analysis: Delete all measurements that are not based on successful personal interviews.
1 2 | tab netto
drop if netto>19
|

How many people contribute measurements and what is the proportion of people contributing at least 10 measurements?
Define the data set as a panel data set.
1 2 3 | **define the data set as panel data
xtset pid syear
xtdes
|
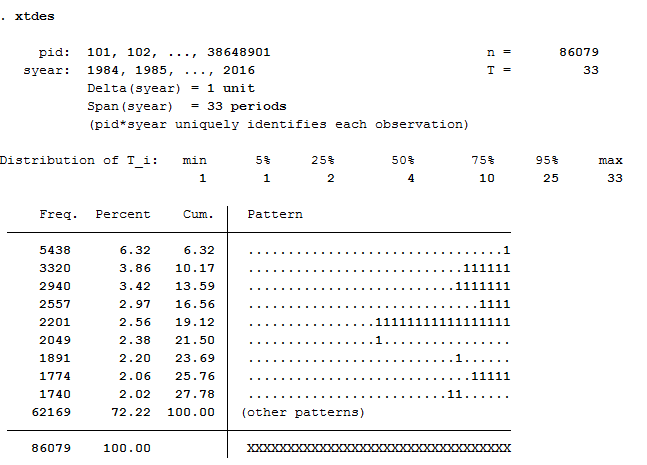
86079 respondents have contributed information within waves a (1984) - bg (2016) and 75% of the 86079 respondents have provided information for at least 10 waves
How many people took part in the survey in 2010 and contributed to continuous measurements until 2014?
1 | xtdes if syear>=2010 & syear<=2014
|
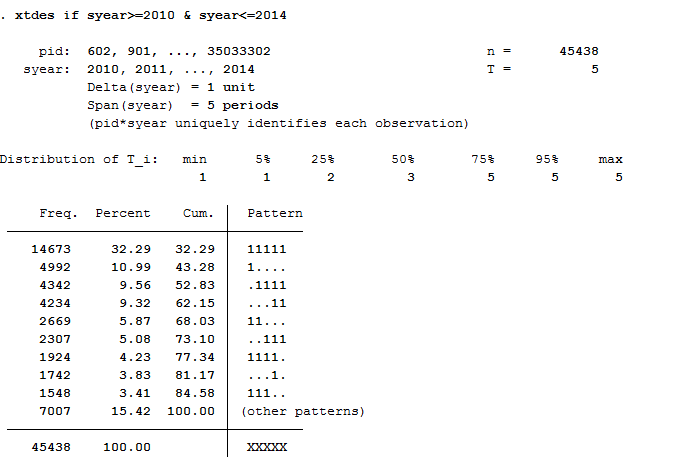
14673 respondents provided continuous information from 2010 to 2014.
Univariate inspection & analysis
How does the mean of life satisfaction change over time?
1 2 3 | *-------------------------------------------------------------------------------
*** Step 4) univariate inspection & analysis
table syear, content (mean plh0182)
|

How high is the proportion of people who will be a) married in 2014 or b) have a migration background. Compare weighted with unweighted frequency tables: Which people are overrepresented in SOEP?
1 2 3 | tab1 pgfamstd migback if syear==2014
tab pgfamstd [aw=phrf] if syear==2014
tab migback [aw=phrf] if syear==2014
|

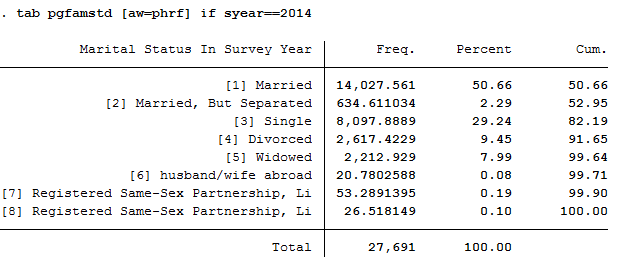
The data show that married people are overrepresented in the SOEP and single people are underrepresented. The weighting makes it representative for Germany again.

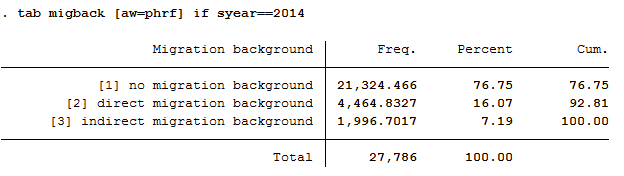
In the SOEP sample, respondents with a direct or indirect migration background are overrepresented.
How many of those persons who report an life satisfaction (scale value 7) in a survey year also indicate the scale value 7 in the following survey year?
1 | xttrans plh0182
|
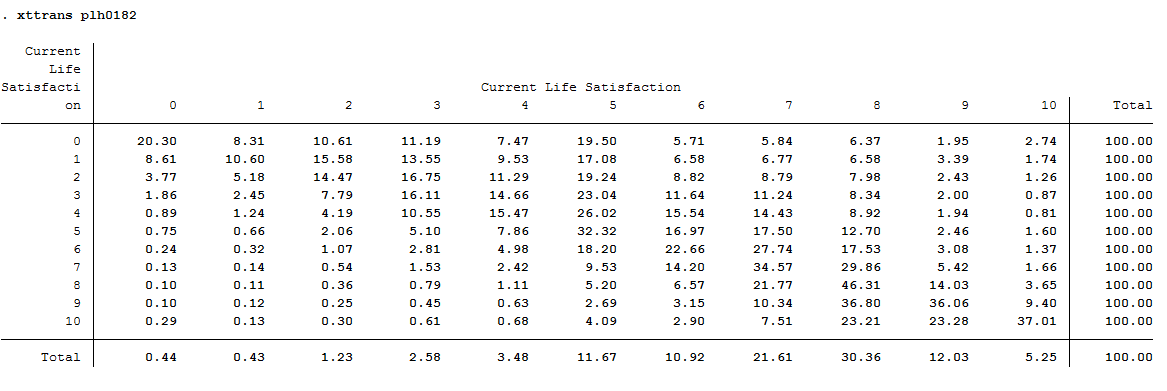
34.57% of the respondents who reported a life satisfaction of 7 again reported a value of 7 in the following year.
Is it more likely that a highly dissatisfied person (value: 0) will be less dissatisfied the following year, or that a very satisfied (value: 10) person will be less satisfied the following year?
1 | xttrans plh0182
|
The rows reflect the initial values, and the columns reflect the final values. People who were completely dissatisfied (value: 0) in the base year remain completely dissatisfied with around 20 % in the following year. About 80% of these dissatisfied people from the base year improve their life satisfaction in the following year. Of the completely satisfied persons (value: 10), about 37% remain just as satisfied in the following year. For 63%, however, life satisfaction worsens. It is more likely that a completely dissatisfied person (value: 0) will become more satisfied in the following year.
Which transitions in marital status can be observed particularly frequently in the data?
1 | xttrans pgfamstd
|
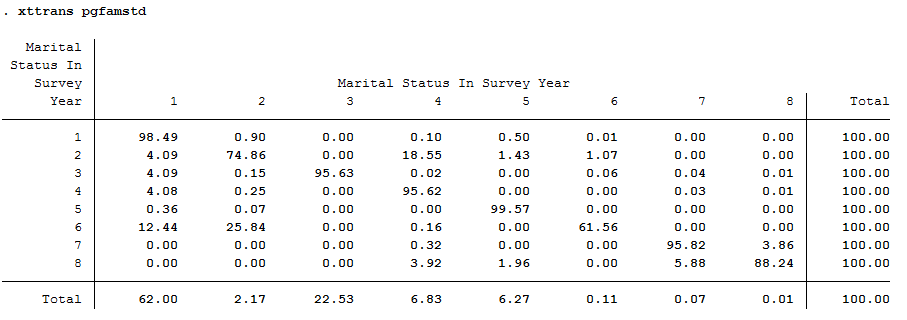
Survey respondents who were married but separated in the base year and declared a divorce as family status in the following year can be observed particularly frequently. (About 19%).
Simple cross sectional analyses
You now want to discover the correlation between marital status and life satisfaction. Is there an effect of marriage on life satisfaction? And if so, is this a sustainable effect?
First, calculate the correlation between family status and life satisfaction in cross section for 2010: Are married people happier than singles?
1 2 3 | *-------------------------------------------------------------------------------
*** Step 5)simple cross sectional analyses
table pgfamstd if syear==2010, content (mean plh0182)
|

At first glance, married couples seem happier than singles.
Now generate a variable that indicates a transition from “single” to “married”.
How many such transitions can you find in the data?
1 2 3 4 | ***perform longitudinal analysis
**define event: transition to marriage
generate to_mar=1 if pgfamstd==1 & l.pgfamstd==3
tab to_mar
|
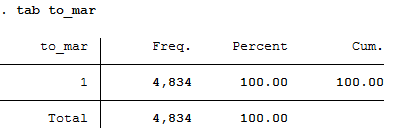
A total of 4834 people can be observed changing from single to married.
What is the average level of life satisfaction immediately after the transition to marriage (i.e. in the first survey in which the transition can be observed) and how high is life satisfaction immediately before the transition to marriage?
1 2 3 4 5 6 7 | **standard way of life-event analysis
sum plh0182 if to_mar==1
sum l.plh0182 if to_mar==1
**alternative way
generate dif_sat= plh0182- l.plh0182
mean dif_sat if to_mar==1
|
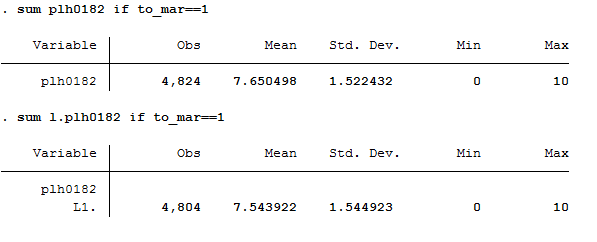

Before the transition to marriage, the average life satisfaction of the respondents is 7.54. in the following year, i.e. after the transition to marriage, the average life satisfaction of the respondents is 7.65. It can be seen that with the transition to marriage, the average life satisfaction rises slightly by 0.11.
Map the complete satisfaction history around the “marriage entry” event [3 years before; 3 years after].
1 2 3 4 5 6 7 8 9 10 | **preparing illustration of trajectory
generate t=0 if to_mar==1 & l.to_mar~=1 &l2.to_mar~=1 & l3.to_mar~=1 & l4.to_mar~=1 & l5.to_mar~=1 & l6.to_mar~=1 & l7.to_mar~=1 & l8.to_mar~=1 & l9.to_mar~=1 & l10.to_mar~=1 & l11.to_mar~=1 & l12.to_mar~=1 & l13.to_mar~=1 & l14.to_mar~=1
replace t=1 if l.t==0
replace t=2 if l2.t==0
replace t=3 if l3.t==0
replace t=-1 if f.t==0
replace t=-2 if f2.t==0
replace t=-3 if f3.t==0
table t, content (mean plh0182 n plh0182)
|
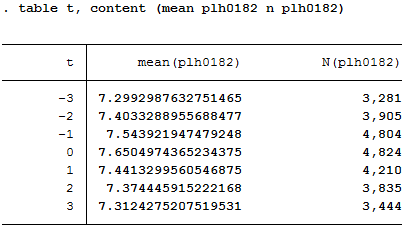
Choose a suitable presentation for your results and let Stata create a graphic.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | ** Preparing graph of event analysis
sort t
cap drop meanplh0182
by t: egen meanplh0182 = mean(plh0182)
cap drop upper
gen upper = .
forval i = -3/3{
su plh0182 if t == `i'
replace upper = r(mean) + 1.96 * r(sd)/sqrt(r(N)) if t == `i'
}
cap drop lower
gen lower = .
forval i = -3/3{
su plh0182 if t == `i'
replace lower = r(mean) - 1.96 * r(sd)/sqrt(r(N)) if t == `i'
}
twoway (line meanplh0182 t) (rcap upper lower t, lcolor("red")) , title("Satisfaction with life relative to year of marriage") legend(label(1 "Avg. life satisfaction") label(2 "95% Conf. interval")) scheme(s1mono) xtitle("Years relative to marriage") ytitle("Avg. life satisfaction")
|
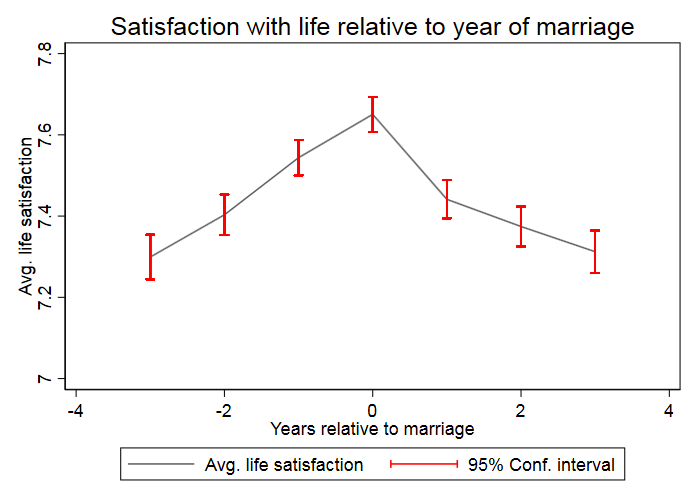
The graph shows that a positive effect on life satisfaction can be observed when the family status changes from single to married. In the following years of the existing marriage, life satisfaction decreases again and approaches the initial satisfaction before the marriage.
Fixed Effects Estimation¶
You want to find out whether certain variables relevant to the labour market, such as work experience or education time, influence a person’s hourly wage. Other variables such as gender or marriage status should also be taken into account. You decide to use the SOEP data to set up a fixed effects estimation model.
Create an exercise path with four subfolders:
Example:
- H:/material/exercises/do
- H:/material/exercises/output
- H:/material/exercises/temp
- H:/material/exercises/log
These are used to store your script, log files, datasets and temporary datasets. Open an empty do file and define your created paths with globals:
1 2 3 4 5 6 7 8 9 | ***********************************************
* Set relative paths to the working directory
***********************************************
global AVZ "H:\material\exercises"
global MY_IN_PATH "\\hume\rdc-prod\distribution\soep-long\soep.v33.1\stata_en\"
global MY_DO_FILES "$AVZ\do\"
global MY_LOG_OUT "$AVZ\log\"
global MY_OUT_DATA "$AVZ\output\"
global MY_OUT_TEMP "$AVZ\temp\"
|
The global „AVZ“ defines the main path. The main paths are subdivided using the globals “MY_IN_PATH”, “MY_DO_FILES”, “MY_LOG_OUT”, “MY_OUT_DATA”, “MY_OUT_TEMP”. The global “MY_IN_PATH” contains the path to your ordered data.
a) Generate your own SOEPWage.dta data set. The data set should contain information on gross monthly wage, marital status and other personal characteristics.
To perform your analysis, you need different SOEP variables. The SOEP offers various options for a variable search:
- Search the questionnaires for useful variables. (for more information visit the chapter Variable Search with Questionnaires)
- Find a suitable variable via the topic list of paneldata.org (for more information visit the chapter Topic Search with paneldata.org)
- Search for a suitable variable using a search term in paneldata.org (for more information visit the chapter Variable Search with paneldata.org)
- Use the documentation provided by the generated variables (for more information visit the chapter Documentation of Generated Data)
Use the various important variables of the ppfadl.dta data set as your start file. Your source file should contain the following variables:
- Person ID "pid"
- Survey year "syear"
- Birth Year "gebjahr"
- The net variable with information on the interview type "netto"
- The weighting variable "phrf"
- The sex of the person "sex"
- Sample Membership "pop"
1 | use pid syear sex gebjahr netto pop phrf using "${MY_IN_PATH}/ppfadl.dta", clear
|
Apply the necessary content variables to your starting data set. You need the following variables for your analysis:
- Employment Status "plb0022"
- Current Gross Labor Income in Euro "pglabgro"
- Actual Work Time Per Week "pgtatzeit"
- Working Experience Full-Time Employment "pgexpft"
- Amount Of Education Or Training In Years "pgbilzeit"
- Marital Status In Survey Year "pgfamstd"
1 2 | merge 1:1 pid syear using "${MY_IN_PATH}/pl.dta", keepus(plb0022) keep(master match) nogen
merge 1:1 pid syear using "${MY_IN_PATH}/pgen.dta", keepus(pglabgro pgtatzeit pgexpft pgbilzeit pgfamstd) keep(master match) nogen
|
Only keep people who have completed an interview and who live in a private household.
1 2 3 4 5 | * Only select people with completed interviews
keep if inrange(netto, 10, 19)
* Only private households
keep if pop==1 | pop==2
|
Since you are only interested in the period from 2012 to 2016 in your analysis, remove all survey information that does not fall within this period. To finish, save your data set.
1 2 | * Period from 2012 to 2016
keep if syear>=2012 & syear<=2016
|
Exercise 1: Prepare your data set
a) Load your created SOEPWage.dta data set. The data set contains information on gross monthly wage, marital status and other personal characteristics.
1 2 3 | *** Exercise 1: Prepare your data set
* a) Load data set
use "${MY_OUT_DATA}/SOEPWage.dta", clear
|
b) Recode all missing values in Stata Missings (.)
1 2 | * b) Recode Missings
mvdecode _all, mv(-8/-1 = .)
|
For more information about the missing codes of SOEP data visit the chapter Missing Conventions
c) Generate the variables “hourly wage” (gross monthly wage/4.33*working time) for persons who have earned at least 1 Euro and have worked at least one hour, “Married vs. Unmarried” and age.
1 2 3 4 5 6 7 | * c) Generate Variables
gen wage = pglabgro/(4.33*pgtatzeit) if pglabgro>=1 & pgtatzeit>=1
gen married = 1 if pgfamstd==1 | pgfamstd==6 | pgfamstd==7 | pgfamstd==8
replace married = 0 if inrange(pgfamstd, 2, 5)
gen age = syear - gebjahr
|
d) Adjust the variable “hourly wage” from outlier values by setting values smaller than the 1st percentile to the same value. Set values greater than 3 times the 99th percentile to 3*99th percentile. Then generate the variable lwage = log(wage).
1 2 3 4 5 6 7 8 9 | * d) Adjust wage variable
sum wage, detail
replace wage = 1/3*r(p1) if wage<1/3*r(p1)
replace wage = 3*r(p99) if wage>3*r(p99) & wage<.
gen lwage = log(wage)
label variable lwage "Log hourly wage"
save "${MY_OUT_DATA}/SOEPWage_temp.dta", replace
|
Exercise 2: Descriptive statistics
a) Define the data set as a panel data set.
1 2 3 | *** Exercise 2: Descriptive statistics
* a)
xtset pid syear // Declaring data as panel data
|
b) What percentage of people participate in all five waves (xtdescribe)
1 2 | * b)
xtdescribe, patterns(16) // -> unbalanced panel
|

42808 respondents have contributed information within waves bc (2012) - bg (2016) and about 40% (17069) of the 42808 respondents have provided information for all waves.
c) Describe the variable “Married” with xttab and xttrans. Take a look at some individual wage (pid=30320901, pid=30932501, pid==3101602, pid==3101801) developments with xtline.
1 2 3 | * c)
* Stability of the relationship status
xttab married
|
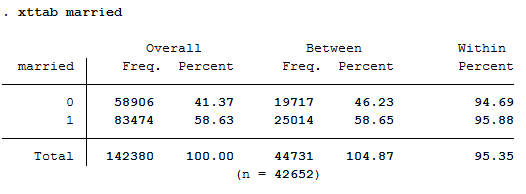
You can observe 41.37 percent of person-year observations with Married==No. At least once 19717 people within the period from 2012 to 2016 have stated not to have been married. 25014 persons reported to have been married at least once during this period. Those who were not married for at least one year responded with “married==no” in 94.69% of the observations. Whereas those who have been married at least once responded in 95.88 percent of the observations with”Married==Yes”. A very stable response behaviour can therefore be observed.
1 2 | * Transition probabilities
xttrans married, freq
|
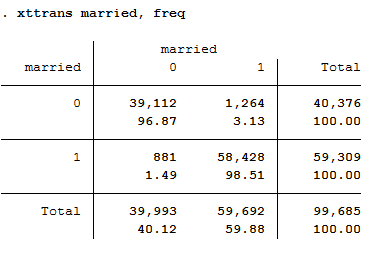
96.87 percent of the person-year observations with “married==no” are also not yet married in the next period. 98.51 percent of the persons who are married indicate that they will also be married in the following period. A stable behaviour of the respondents can be seen.
1 2 | * Individual sequences of "wage"
xtline wage if pid==30320901 | pid==30932501 | pid==3101602 | pid==3101801, overlay
|
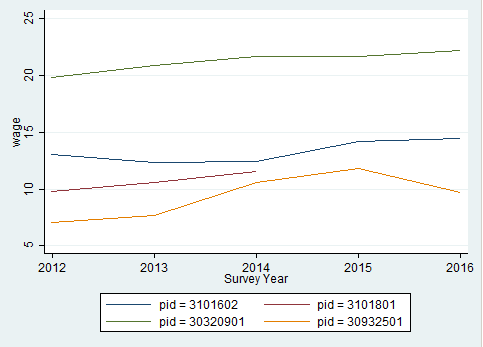
The graphic shows a comparison of the hourly wage for four different respondents.
Exercise 3: Pooled OLS Regression
a) Execute a pooled OLS regression with “Log hourly wage” as dependent variable and “Married”, “Gender”, “Work experience” and “Training time” as independent variables. Interpret the coefficients for “married”, “gender” and “length of training”. Why are these not causal effects?
1 2 3 | *** Exercise 3: Pooled OLS Regression
* a) Pooled OLS
reg lwage married sex pgexpft pgbilzeit
|
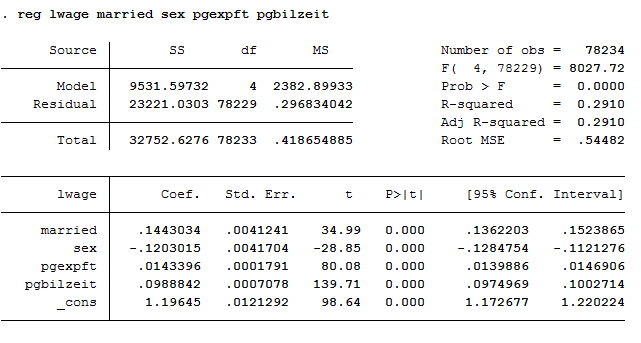
The variables married, sex and pgbilzeit most likely correlate with other disregarded/unobserved variables that have an effect on the wage. For example, women work more frequently in occupations with lower wages.
b) Run the regression again with the option “vce(cluster persnr)” to get clustered standard errors. How do the standard errors of the coefficients change?
1 2 | * b) Pooled OLS with cluster standard errors
reg lwage married sex pgexpft pgbilzeit, vce(cluster pid)
|
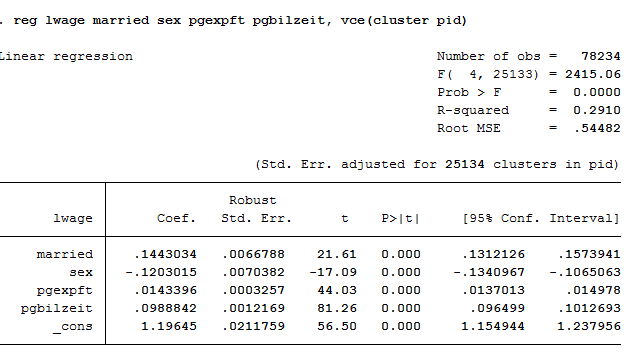
The standard errors are getting bigger.
Exercise 4: Fixed Effects
a) Subtract the person-specific mean value from each variable of the model. Use the “egen” function. Ideally you should also use a loop.
1 2 3 4 5 6 7 8 9 10 11 12 | *** Exercise 4: Fixed Effects
* a) Subtract person-specific averages
gen sample = 1
foreach var in lwage married sex pgexpft pgbilzeit {
bysort pid: egen `var'Mean = mean(`var')
replace `var'Mean = . if `var'==.
gen `var'Demeaned = `var' - `var'Mean
replace sample = 0 if `var'==.
}
bysort pid (sample): replace sample = sample[1]
|
b) Estimate the Fixed Effects model with the previously generated variables. Why is no coefficient estimated for “gender”? How do the coefficients change compared to the pooled OLS estimate? Is the effect of “married” now causally interpretable?
1 | reg lwageDemeaned marriedDemeaned sexDemeaned pgexpftDemeaned pgbilzeitDemeaned, vce(cluster pid) nocons
|
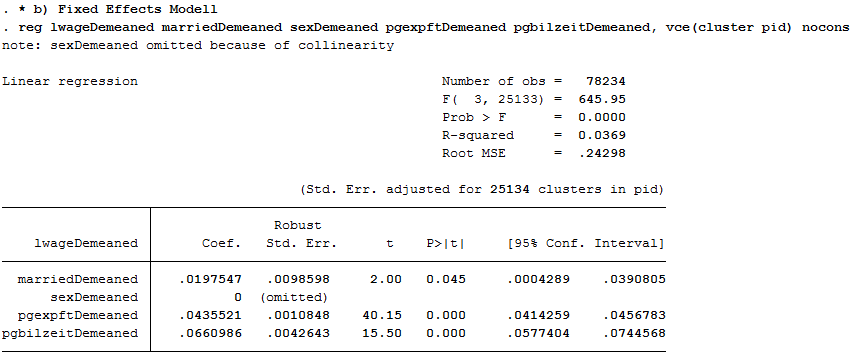
No coefficient was estimated for sex because sex was stable over time for all observations. The coefficient of married is now significant at the 5% level!
c) Now estimate the Fixed Effects model using the command “xtreg lwage married sex pgexpft pgbilzeit, fe “. What do you notice about the coefficients compared to task 4 b)? And with the standard errors?
1 2 | * c) xtreg, fe
xtreg lwage married pgexpft pgbilzeit, fe vce(cluster pid)
|
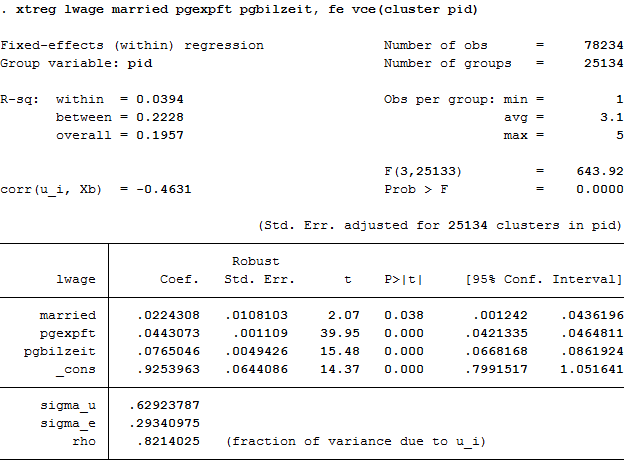
The coefficients are not identical with 4 b) and the standard errors become larger, because model b) does not take into account the estimation of mean values in the standard errors.
d) Now add dummy variables for the years (i.syear). What happens with the effect of “labour market experience”?
1 2 | * d) xtreg with dummy
xtreg lwage married pgexpft pgbilzeit i.syear, fe vce(cluster pid)
|
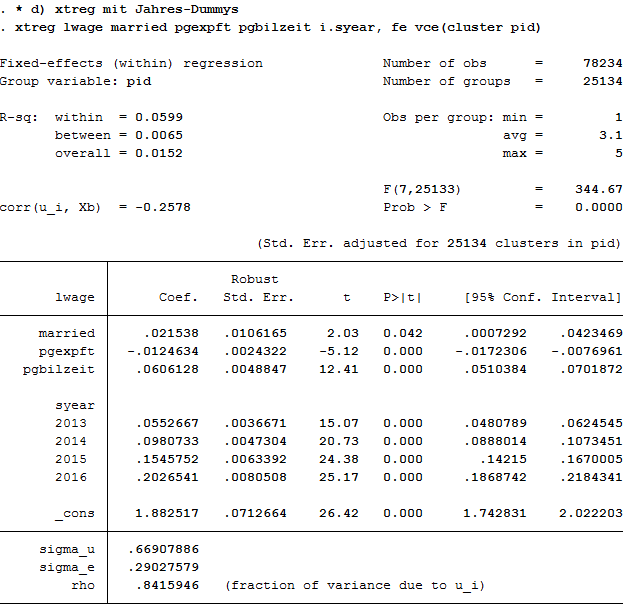
Effects on the variables remain significant. The model could possibly be specified on a case by case basis. The Mincer equation is based on (potential) labour market experience squared.
e) Now you can also square labour market experience into the model. To what extent does the effect of labour market experience change compared to task 5d)?
1 2 | * e) expft squared
xtreg lwage married c.pgexpft##c.pgexpft pgbilzeit i.syear, fe vce(cluster pid)
|
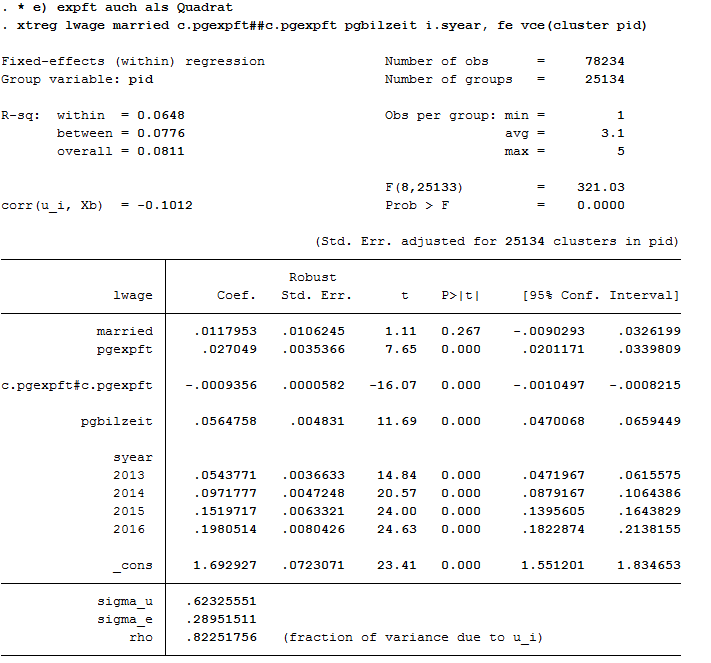
The coefficients of pgexpft and pgexpft^2 remain significant whereas the coefficient for married is no longer significant.
1 | graph twoway (func y = _b[pgexpft]*x + _b[c.pgexpft#c.pgexpft]*x*x, range(0 40))
|
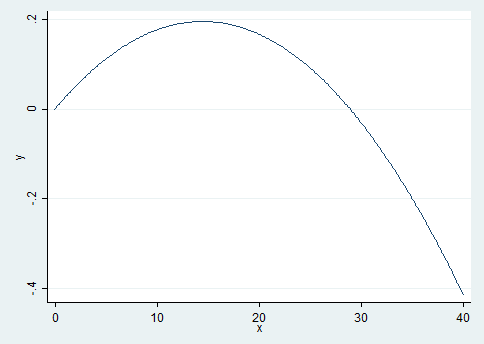
The graph shows that the effects of the labour market experience decrease after approximately 15 years of professional experience.
f) Now estimate the model from task 5e) with longitudinal section weights. Why is the number of cases now significantly smaller? Why could the coefficient of “pgbilzeit” have changed?
Tip
Create your own longitudinal person weights e.g. longitudinal person weight from wave A to wave D. Take the starting wave cross-sectional weight (aphrf) and multiply through by each following wave staying factor, as in the following example: gen adphrf=aphrf*bpbleib*cpbleib*dpbleib
Since you are looking at the period 2012-2016, you must create a suitable longitudinal weight. To do this, use the phrf data set from the RAW subdirectory. Apply the required variables on your analysis data set and generate your period-related longitudinal section weight. To understand the structure of the data distribution file and the location of the different data sets, visit the chapter Data Sets SOEP-Core. For more information about the weighting data sets and other survey data sets, visit the chapter Survey Data.
1 2 3 4 5 6 7 | * f) Fixed Effects weighted
global MY_IN_PATH2 "\\hume\rdc-prod\complete\soep-core\soep.v33.2\stata_en\"
rename pid persnr
merge m:1 persnr using "${MY_IN_PATH2}/phrf.dta", nogen keep(master match) keepus(bcphrf bdpbleib bepbleib bfpbleib bgpbleib)
gen wlong = bcphrf*bdpbleib*bepbleib*bfpbleib*bgpbleib
label variable wlong "Weighting BC-BG"
rename persnr pid
|
Now estimate the model from 5e) and use the created weight.
1 | xtreg lwage married c.pgexpft##c.pgexpft pgbilzeit i.syear [pw=wlong], fe vce(cluster pid)
|

The number of observations is now much smaller. The effect of pgbilzeit is stronger than before. Pgbilzeit has a lower effect in the wlong==0 group, where the return is different for each additional educational year. People in the wlong===0 group may not get the return for the additional education they expected on the local labour market and may therefore move -> higher probability for dropout.
Working with SOEP Regional Data¶
SOEP offers diverse possibilities for regional and spatial analysis. With the anonymized regional information on the residences of SOEP respondents (households and individuals), it is possible to link numerous regional indicators on the levels of the states (Bundesländer), spatial planning regions, districts, and postal codes with the SOEP data on these households. However, specific security provisions must be observed due to the sensitivity of the data under data protection law. Accordingly, you are not allowed to make statements on, e.g., place of residence or administrative district in your analyses, but the data does provide valuable background information.

For more Information and to get access visit Regional Data
For your research project you want to measure current (year 2016) urban-rural differences in the population. You are particularly interested in the differences in political interest and the different satisfaction variables provided by the SOEP. You also want to take into account demographic differences in gender and age. In order to be able to evaluate the research potential, you should get an overview. For regional analyses, for example, the community size classes from the regional data are suitable.
Create an exercise path with four subfolders:
Example:
- H:/material/exercises/do
- H:/material/exercises/output
- H:/material/exercises/temp
- H:/material/exercises/log
These are used to store your script, log files, datasets and temporary datasets. Open an empty do file and define your created paths with globals:
1 2 3 4 5 6 7 8 9 10 | ***********************************************
* Set relative paths to the working directory
***********************************************
global AVZ "H:\material\exercises"
global MY_IN_PATH "\\hume\rdc-prod\complete\soep-core\soep.v33.2\stata_en\"
global region "\\hume\soep-region\DATA\soep33_de\"
global MY_DO_FILES "$AVZ\do\"
global MY_LOG_OUT "$AVZ\log\"
global MY_OUT_DATA "$AVZ\output\"
global MY_OUT_TEMP "$AVZ\temp\"
|
The global „AVZ“ defines the main path. The main paths are subdivided using the globals “MY_IN_PATH”, “MY_DO_FILES”, “MY_LOG_OUT”, “MY_OUT_DATA”, “MY_OUT_TEMP”. The global “MY_IN_PATH” contains the path to your ordered data.
a) Prepare a cross-sectional analysis data set covering the survey year 2016 (wave bg).
To perform your analysis, you need different SOEP variables. The SOEP offers various options for a variable search:
- Search the questionnaires for useful variables. (for more information visit the chapter Variable Search with Questionnaires)
- Find a suitable variable via the topic list of paneldata.org (for more information visit the chapter Topic Search with paneldata.org)
- Search for a suitable variable using a search term in paneldata.org (for more information visit the chapter Variable Search with paneldata.org)
- Use the documentation provided by the generated variables (for more information visit the chapter Documentation of Generated Data)
Your source file should contain the following variables:
- Never Changing Person ID "persnr"
- Original Household Number "hhnr"
- Current Wave Household Number "bghhnr"
- The sex of the person "sex"
- Year of birth "gebjahr"
- Survey Status 2016 "bgnetto"
- Sample Membership 2016 "bgpop"
- Weighting Factor 2016 "bgphrf"
- Satisfaction With Health "bgp0101"
- Satisfaction With Sleep "bgp0102"
- Satisfaction With Work "bgp0103"
- Satisfaction With Housework "bgp0104"
- Satisfaction With Household Income "bgp0105"
- Satisfaction With Personal Income "bgp0106"
- Satisfaction With Dwelling "bgp0107"
- Satisfaction With Amount Of Leisure Time "bgp0108"
- Satisfaction With Child Care "bgp0109"
- Satisfaction With Family Life "bgp0110"
- Satisfaction With Social Life "bgp0111"
- Zufriedenheit mit Demokratie "bgp0112"
- Political Interests "bgp143"
- Current Sample Region "bgsampreg"
- Federal State "bgbula"
- Spatial category by BBSR "bgregtyp"
- Community Class Sizes “ggk”
Use the various important variables of the ppfad.dta data set as your start file.
1 | use hhnr persnr bghhnr sex gebjahr bgnetto bgpop using ${MY_IN_PATH}\ppfad.dta, clear
|
Keep people who completed a questionnaire in 2016 and live in a private household.
1 2 3 4 5 6 | * Keep people who completed a questionnaire in 2016 and live in a private household
keep if bghhnr>0 & inrange(bgnetto, 10, 29) & inlist(bgpop, 1, 2)
keep hhnr persnr bghhnr sex gebjahr bgnetto bgpop
merge 1:1 persnr using ${MY_IN_PATH}\phrf.dta, keep(match master) keepusing (bgphrf) nogenerate
tempfile ppfad
save `ppfad'
|
Prepare the different data sets bgp, bghbrutto, regiobl
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | * Prepare data set bgp
use ${MY_IN_PATH}\bgp.dta, replace
keep persnr hhnr bghhnr bgp01* bgp143
tempfile bgp
save `bgp'
* Prepare data set bghbrutto
use ${MY_IN_PATH}\bghbrutto.dta, replace
keep hhnr bghhnr bgsampreg bgbula bgregtyp
tempfile bghbrutto
save `bghbrutto'
* Prepare data set regionl
use ${region}\regionl_v33.dta, replace
keep if syear==2016
keep syear hhnr hhnrakt ggk
rename hhnrakt bghhnr
tempfile regionl
save `regionl'
|
Merge all data sets.
1 2 3 4 5 | * Merge all data sets
use `ppfad'
merge 1:1 persnr using `bgp', keep(match master) nogenerate
merge m:1 bghhnr hhnr using `regionl', keep(match master) nogenerate
merge m:1 bghhnr hhnr using `bghbrutto', keep(match master) nogenerate
|
Recode negative values into missings.
1 2 | * Recode negative values into missings
mvdecode sex gebjahr bgp01* bgp143,mv(-5/-1)
|
Categorize the community class sizes of the SOEP regional data set.
1 2 3 4 5 6 7 8 9 10 11 12 | * Categorize community class size
gen ggk_cat=.
replace ggk_cat=-1 if ggk==-1
replace ggk_cat=1 if ggk==1 | ggk==2
replace ggk_cat=2 if ggk==3
replace ggk_cat=3 if ggk==4 | ggk==5
replace ggk_cat=4 if ggk>5 & ggk<=7
lab var ggk_cat "Community Size categorised"
lab def ggk_cat -1 "No information" 1 "<=5000" 2 "5001 - 20000" 3 "20001 - 100000" ///
4 ">100000"
lab val ggk_cat ggk_cat
|
Generate an age variable.
1 2 3 4 5 6 7 8 9 10 11 | * Generate age variable
gen alter= 2016-gebjahr if gebjahr > 0
gen alter_cat=1 if alter<=20
replace alter_cat=2 if alter>20 & alter<=30
replace alter_cat=3 if alter>30 & alter<=65
replace alter_cat=4 if alter>65 & alter<=120
lab var alter "age"
lab var alter_cat "age categorized"
lab def alter_cat 1 "<=20" 2 "21-30" 3 "31-65" 4 ">65"
lab val alter_cat alter_cat
|
Categorize federal states variable.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | * Categorize federal states
gen bgbula_cat=.
* Schleswig-Holstein + Hamburg
replace bgbula_cat=1 if bgbula==1 | bgbula==2
* Lower Saxony + Bremen
replace bgbula_cat=2 if bgbula==3 | bgbula==4
* Mecklenburg Western Pomerania + Brandenburg
replace bgbula_cat=3 if bgbula==13 | bgbula==12
* Saarland + Rhineland Palatinate
replace bgbula_cat=4 if bgbula==7 | bgbula==10
* Northrhine-Westphalia
replace bgbula_cat=5 if bgbula==5
* Hesse
replace bgbula_cat=6 if bgbula==6
* Baden-Württemberg
replace bgbula_cat=7 if bgbula==8
* Bavaria
replace bgbula_cat=8 if bgbula==9
* Berlin
replace bgbula_cat=9 if bgbula==11
* Saxony
replace bgbula_cat=10 if bgbula==14
* Saxony-Anhalt
replace bgbula_cat=11 if bgbula==15
* Thuringia
replace bgbula_cat=12 if bgbula==16
lab var bgbula_cat "Federal states categorized"
lab def bgbula_cat 1 "Schleswig-Holstein/Hamburg" 2 "Lower Saxony/Bremen" 3 "Mecklenburg Western Pomerania/Brandenburg" ///
4 "Saarland/Rhineland Palatinate" 5 "Northrhine-Westphalia" 6 "Hesse" ///
7 "Baden-Wuerttenberg" 8 "Bavaria" 9 "Berlin" 10 "Saxony" 11 "Saxony-Anhalt" 12 "Thuringia"
lab val bgbula_cat bgbula_cat
drop bgbula
rename bgbula_cat bgbula
|
Put the variables in your preferred order and save your data set.
1 2 3 4 5 | * Order demography and identifiers first
order persnr hhnr bghhnr syear sex gebjahr alter alter_cat bgsampreg bgbula ggk ///
ggk_cat bgregtyp
save ${MY_OUT_DATA}\zeit_online.dta, replace
|
b) You want to get an initial overview of regional differences in satisfaction with various aspects in Germany. Use the variable bgsampreg and cross-stabilize the variable with all satisfaction variables to identify differences between East and West Germany, display the absolute and relative frequencies.
To save the tables, save them in a log file.
1 2 3 4 5 6 7 8 9 10 11 | ********************************************************************************
capture log close
log using "${MY_LOG_OUT}\satisfaction.log", replace
* Life satisfaction
local varlist bgp0101 bgp0102 bgp0103 bgp0104 bgp0105 bgp0106 bgp0107 bgp0108 ///
bgp0109 bgp0110 bgp0111 bgp0112
foreach x of local varlist {
tab bgsampreg `x' [aw= bgphrf] , row
}
|



To view all tables, look at your generated log file.
c) Now take a closer look at satisfaction with various aspects of life with the help of SOEP regional data. Use the community size classes. Create a table showing you satisfaction with different aspects of life and revealing differences by gender, age, community size class and federal state.
1 2 3 4 5 6 7 8 | foreach x of local varlist {
* Tabulation of satisfaction by size of community and federal state
table `x' sex alter_cat, by(bgbula ggk_cat) contents(freq) column row stubwidth(20) cellwidth(8) csepwidth(2) nomissing
* Tabulation of satisfaction by size of community
table `x' sex alter_cat, by(ggk_cat) contents(freq) column row stubwidth(20) cellwidth(8) csepwidth(2) nomissing
* Tabulation of satisfaction by federal state
table `x' sex alter_cat, by(bgbula) contents(freq) column row stubwidth(20) cellwidth (8) csepwidth(2) nomissing
}
|

To view all tables, look at your generated log file. As you can see, SOEP regional data can be used to analyze variables at the smallest regional levels.
d) Create a table that shows you the political interest differentiated by age, gender and community size class for Bavaria
1 2 3 4 5 6 7 | ********************************************************************************
capture log close
log using "${MY_LOG_OUT}\political_interest.log", replace
* Political interest
* Tabulation of political interest by size of community for Bavaria
table bgp143 sex alter_cat if bgbula==8, by(ggk_cat) contents(freq) column row stubwidth(20) cellwidth (8) csepwidth(2) nomissing
|

It becomes clear that the SOEP offers a wide range of possibilities for region-related analyses. It is possible to allocate a multitude of regional indicators at the level of the federal states, the regional planning regions, the districts and the postal codes.